
En kunstig intelligens-modell må trenes før den kan utføre oppgaver for oss. Jo flere oppgaver modellen skal utføre, desto mer trening er nødvendig. Hvilken oppgave du vil at modellen skal utføre bestemmer hvordan treningen foregår.
En KI-modell blir ikke bedre enn treningen den går igjennom. Vil du ha gode resultater, må modellen trenes på gode data – og på riktig mengde data. Store modeller krever mye trening, små modeller klarer seg med mindre trening.
Treningsdata er en av de største utfordringene for utviklingen av nye, avanserte KI-modeller. Det er vanskelig å få tak i nok data av høy kvalitet. De store språk- og bildemodellene er allerede trent på nesten alt innhold som finnes på internett. Hvor skal man finne mer tekst og flere bilder for å trene nye modeller, som krever mange ganger mer treningsdata enn det som finnes?
Skjevheter i treningsdata er også en utfordring. De fleste bilder som finnes av leger er hvite menn. Da vil modellene trenes opp til at leger er hvite menn, mens realiteten er at leger kan være både kvinner og menn, av alle etnisiteter.
Tilsvarende har det vist seg at KI-modeller som brukes til bekjempelse av kriminalitet noen ganger trenes på data som inneholder skjevheter. En overvekt av kriminalitet som rapporteres, skjer i fattige områder. I disse områdene bor det ofte mange med minoritetsbakgrunn, siden flyktninger og innvandrere som kommer til landet ofte har begrensede ressurser. Modellene trenes dermed opp til at det er større sannsynlighet for at mennesker med innvandrerbakgrunn begår kriminalitet, selv om dette ikke nødvendigvis stemmer med statistikken.
Det finnes i utgangspunktet tre ulike måter å trene kunstig intelligens på. De ulike metodene egner seg for oppgaver. Noen ganger kombineres flere metoder.
Assistert trening er den vanligste formen for trening av kunstig intelligens. Det gjøres ved å trene modellen på data som er merket. Et bilde av en fugl vil for eksempel merkes med «fugl» og eventuelle andre aktuelle objekter og egenskaper. Bildet lastes inn i modellen, resultatet modellen kommer frem til sammenlignes med det bildet er merket med, og så justeres parameterne i modellen slik at de gir et mer riktig resultat neste gang. Dette gjentas helt til modellen kommer frem til ganske riktig resultat hver gang.
Assistert trening brukes i modeller som skal brukes til å kjenne igjen eller generere for eksempel bilder eller andre former for data.
Assistert trening i praksis:
Treningsdataene merkes med egenskapene modellen skal kjenne igjen. I eksemplet skal modellen kjenne igjen et bilde av tallet 6.
Målet med treningen er at den riktige output-noden (den som representerer tallet 6) skal aktiveres, fordi modellen kjenner igjen bildet som tallet 6. At en node er «aktivert» vil si at den har en verdi nær 1. Samtidig skal de andre output-nodene har en verdi nær 0.
Før modellen er ferdig trent vil en tilfeldig output-node aktiveres, og verdien på hver av output-nodene vil variere tilfeldig mellom 0 og 1.
Når feil node aktiveres for et treningsbilde, vil modellen justere parameterne i det nevrale nettverket. Vektene i det siste laget før output-laget vil justeres slik at output-noden for tallet 6 får en verdi nærmere 1 og de andre output-nodene får en verdi nærmere 0. Så justeres parameterne i det nest siste laget tilsvarende og så videre gjennom hele det nevrale nettverket.
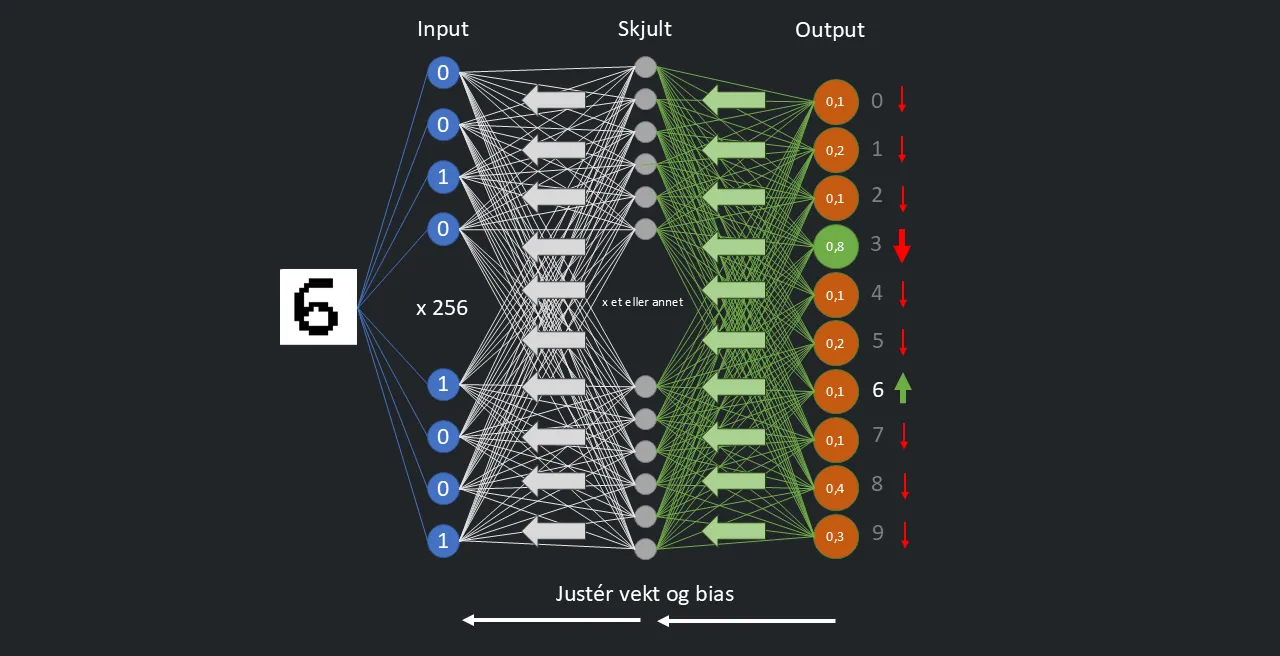
Så gjentas prosessen med et nytt bilde. Etter hvert som modellen trenes på flere bilder, vil parameterne etter hvert bli justert til verdier som gir riktig resultat på alle bildene. Da er modellen ferdig trent.
Ved uassistert trening får modellen store mengder umerkede data, og vil selv finne mønstre og sammenhenger i dataene.
Når modellen er ferdig trent, vil nye data sammenlignes med mønstre og sammenhenger fra treningen. Slik vil den kunne kategorisere data, eller avsløre data som avviker fra treningsdataene.
Et vanlig bruksområde for uassistert trening er anbefalingsmodeller, for eksempel de som anbefaler deg andre produkter når du handler i en nettbutikk.
Et annet vanlig bruksområde er svindelbekjempelse. En bank kan for eksempel trene en modell på millioner av transaksjoner. Nå en person gjennomfører en ny transaksjon, vil systemet sjekke om transaksjonen avviker fra mønstrene den har identifisert i treningen, og i tilfelle flagge transaksjonen som mulig svindel.
Språkmodeller trenes også ved hjelp av uassistert trening, men med en litt annen teknikk.
En tekststreng fra treningsdatene sendes inn som treningsdata i modellen. Ett ord i tekststrengen er fjernet, og modellen skal identifisere hvilket ord som mangler. Treningen fungerer på samme måte som assistert trening, men oppgaven er altså å finne ut av hvilket ord som mangler.
Når modellen identifiserer riktig ord i alle (eller nesten alle) setninger, er modellen ferdig trent.
Forsterkende trening er en treningsmetode som belønner modellen for å komme frem til riktig resultat. Forsterkende læring kan brukes alene, eller i kombinasjon med assistert eller uassistert trening.
Et eksempel på forsterkende trening kan være en selvkjørende bil som skal lære å lukeparkere. Jo nærmere fortauskanten den selvkjørende bilden klarer å parkere, desto flere poeng får modellen. Hvis bilen treffer en annen bil, får den null poeng. Etter å ha trent på lukeparkering tusenvis av hanger, vil modellen komme frem til den perfekte teknikken for å parkere helt inntil fortauskanten uten å treffe noen andre bilder.
Et av de mest kjente eksemplene på forsterkende trening er da Google DeepMind lot en AI-modell spille ulike Atari TV-spill. Modellen fikk ingen trening i spillet, den fikk kun «se» skjermbilder og poengsummen som ble oppnådd. Oppgaven modellen fikk var å maksimere poengsummen.
Resultatene var spesielt tydelig i spillet Breakout, hvor målet er å slå en ball mot en vegg med murstein. Hver gang ballen treffer en murstein forsvinner den, og spilleren får poeng.

I begynnelse spilte AI-modellen dårlig, og fikk ingen poeng. Men etter noen få spill lærte den at den skulle bevege racketen i bunnen av skjermen slik at ballen ble slått opp igjen mot mursteinene. Da fikk den poeng.
Etter 200 spill spilte AI-modellen allerede som en ekspert, og etter 600 spill hadde den lært å styre ballen slik at den åpnet en tunnel gjennom muren, slik at ballen fjernet hele muren ovenfra. Dette er den mest effektive måten å få mange poeng i Breakout.
Språkmodeller bruker også forsterkende trening. Etter at grunntreningen er gjennomført med uassistert trening, brukes en variant av forsterkende trening som kalles forsterkende trening fra menneskelig respons (reinforcement learning from human feedback - RLHF) for å trene modellen på å svare mest mulig menneskelig. Flere varianter av et svar presenteres til et menneske, som rangerer svarene. Rangeringen fungerer som belønning, og trener modellen på å velge de svarene mennesker foretrekker.
En annen måte språkmodeller bruker forsterkende læring er i resonnerende språkmodeller. De bruker forsterkende trening for å lære seg resonnering. Under treningen belønnes modellen for å velge riktig metode og komme frem til riktige svar på komplekse problemer.
Det er vanlig at AI-modeller bruker flere treningsmetoder. Språkmodeller bruker både uassistert og forsterkende trening, slik jeg har beskrevet over. Generative bildemodeller bruker også forsterkende trening i tillegg til assistert trening. Etter at grunntreningen er gjennomført med assistert trening, fintrenes modellen ved hjelp av forsterkende trening.
Den forsterkende treningen foregår ved at én versjon av modellen genererer bilder som sendes til en annen modell. Den andre modellen rangerer hvilke bilder den synes er best, og sender rangeringen tilbake til den første modellen. Denne bruker rangeringen som belønning i treningen.
