
Kunstig intelligens har tatt verden med storm. Teknologien som tidligere var forbeholdt det største virksomhetene, er nå tilgjengelig for alle. Den kan lese og skrive tekst, tolke og lage bilder, analysere data og spå om fremtiden, ofte bedre enn oss mennesker. Det kan virke som magi, men det er det ikke. Kunstig intelligens er egentlig bare matematikk. Her er en forklaring på hvordan kunstig intelligens virker.
Når ChatGPT leser og skriver tekst som et menneske, er det lett å få inntrykk av at datamaskiner nå har fått menneskelig intelligens. Det har den ikke. Selv om nevrale nettverk, som er teknologien bak kunstig intelligens, er oppkalt etter hjernen vår, fungerer de to helt forskjellig. Her skal jeg forsøke å forklare deg hvordan kunstig intelligens bruker matematikk for å skape de utrolige resultatene den gjør.
La meg starte med to forbehold: 1) Jeg gjør noen grove forenklinger for å gjøre prinsippene forståelige. 2) Selv om jeg har forenklet forklaringen, er dette fortsatt en litt teknisk artikkel.
For å illustrere hvordan kunstig intelligens virker, tar jeg utgangspunkt i en modell som skal kjenne igjen tallene 0 til 9. Det er en relativt enkel oppgave, men prinsippene er de samme som brukes i mer avanserte modeller. Bildemodeller, språkmodeller, lydmodeller, analysemodeller og prediksjonsmodeller følger alle de samme prinsippene i grove trekk.
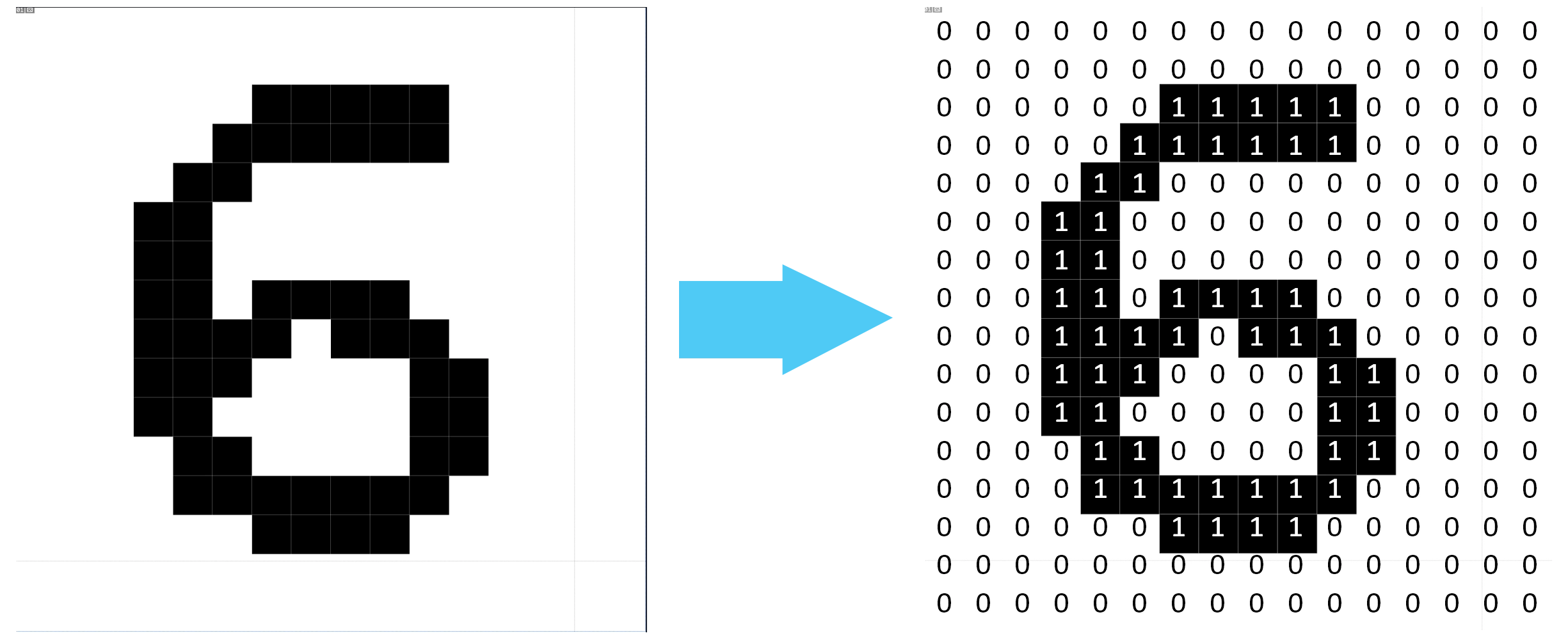
La oss ta utgangspunkt i et bilde på 16 x 16 punkter som inneholder tallet 6. Her er forklaringen på hvordan en kunstig intelligens-modell kan kjenne igjen hvilket tall som vises på bildet.
Det første som skjer, er at bildet gjøres om til verdier. I vårt tilfelle er verdien 0 i de hvite punktene og 1 i de sorte punktene. Vi får da en rekke med 256 verdier. Det samme skjer i mer avanserte bildemodeller. I fargebilder blir hvert punkt tre verdier, en for hver av fargen rød, grønn og blå. I en språkmodell vil hvert tegn i teksten gjøres om til en verdi. I en lydmodell vil lyden gjøres om til verdier som representerer frekvens, styrke og tid for hvert enkelt «lydpunkt».
Kunstig intelligens bruker en teknisk infrastruktur som kalles et nevralt nettverk. Det bestå av flere lag med «noder» som er koblet sammen med hverandre. Navnet nevralt nettverk kommer av at strukturen minner om måten hjernen vår er bygget opp med hjerneceller som er koblet til hverandre med synapser. Selv om kunstig intelligens og hjernen vår er bygget opp med strukturer som ligner på hverandre, så fungerer de imidlertid helt ulikt.
Et nevralt nettverk består i utgangspunktet av minst tre lag: Et input-lag, et skjult lag og et output-lag.
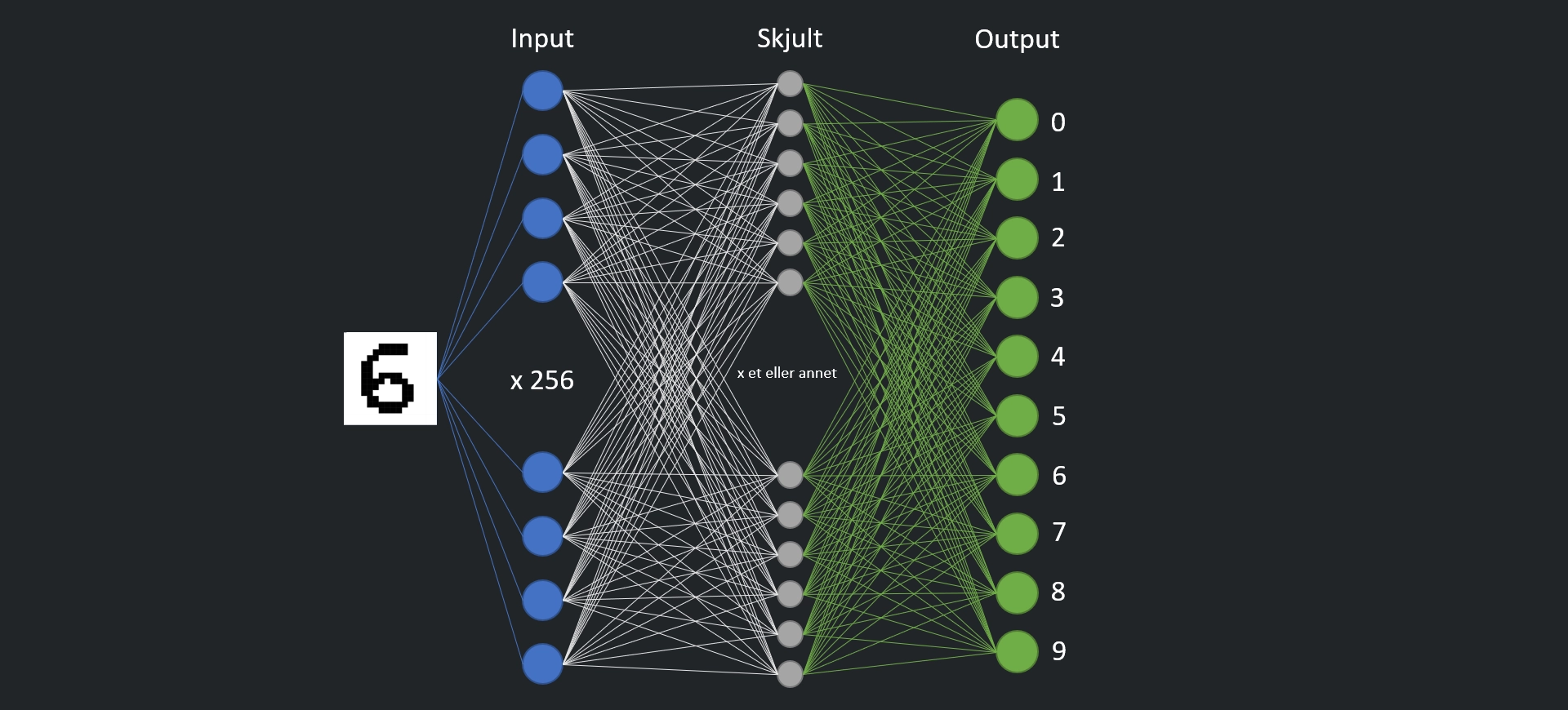
Input-laget er der vi sender inn verdiene vi skal analysere. I vårt eksempel har input-laget 256 noder, som hver representerer en av de 256 verdiene 0 eller 1.
Det skjulte laget er der selve jobben gjøres. Det kan bestå av hundrevis eller tusenvis av noder. Jeg kommer tilbake til hvordan det skjulte laget fungerer.
Output-laget representerer resultatet vi ser etter. Siden vi i vårt eksempel ser etter tallene 0 til 9, består output-laget vårt av 10 noder, en for hver mulige verdi.
I utgangspunktet er alle nodene i input-laget koblet til hver enkelt node i det skjulte laget, og hver enkelt noe i det skjulte laget er koblet til hver enkelt node i output-laget.
Når alle verdiene i input-laget er behandlet av det skjulte laget, vil resultatet bli en verdi mellom 0 og 1 i hver av nodene i output-laget. Den noden som har en verdi nærmest 1 angir resultatet av analysen. I vårt tilfelle vil altså noden som representerer tallet 6 ha en verdi nær 1, mens de andre nodene i output-laget vil ha en verdi nærmere 0.
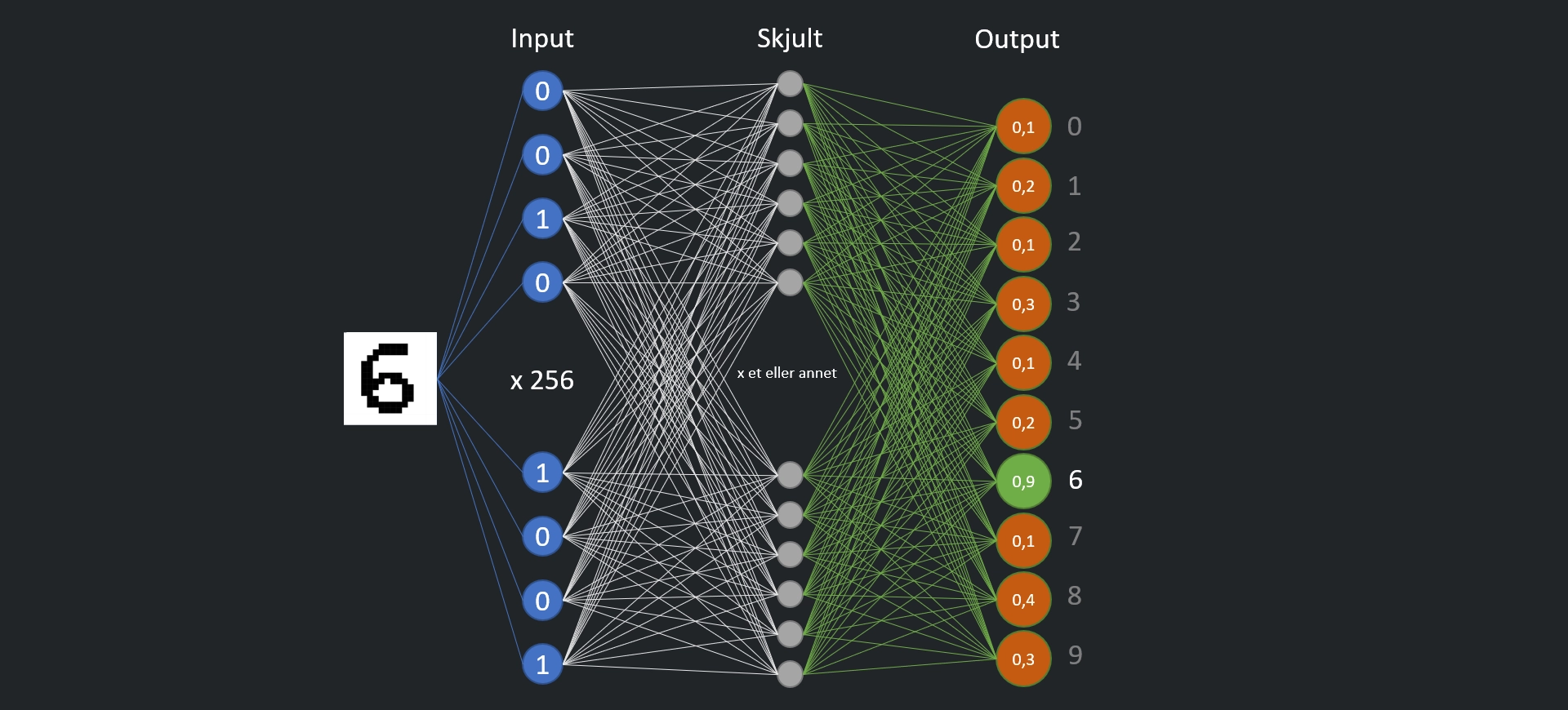
Hva skjer i det skjulte laget, som gjør at 256 verdier i input-laget ender opp med at 6-noden bli omtrent 1 og de andre nodene i output-laget blir omtrent 0?
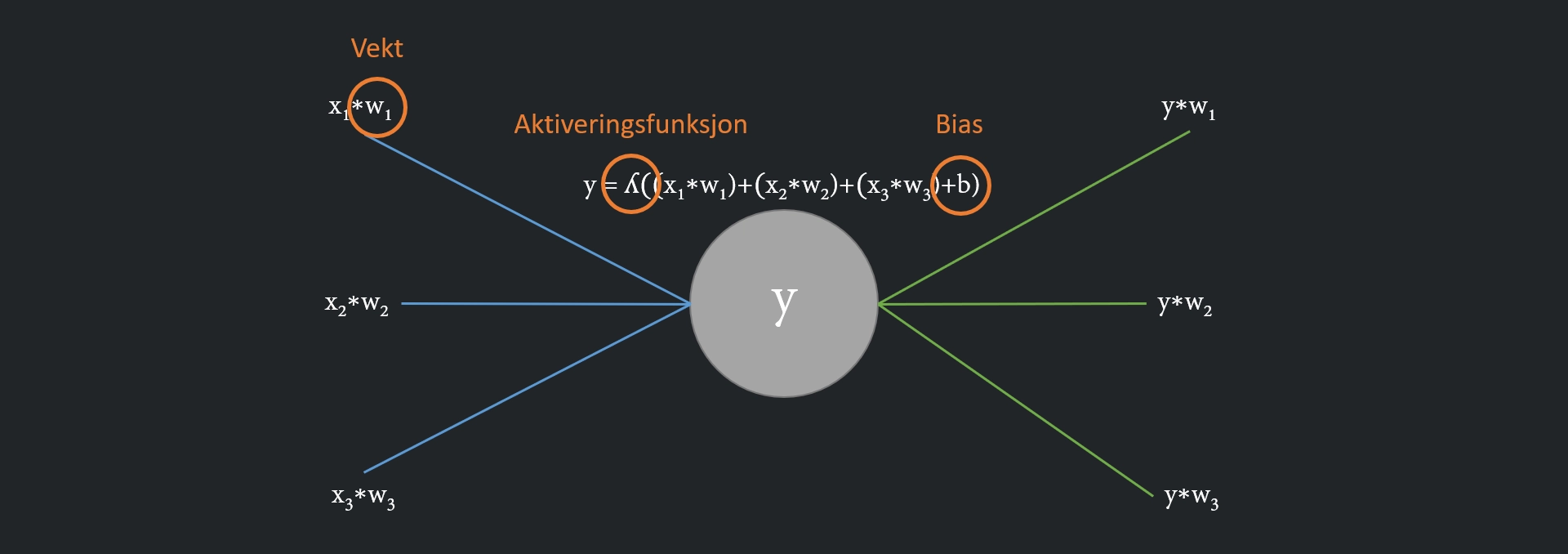
I praksis er det avansert matematikk. Hver enkelt kobling mellom to noder har en vekt, en faktor som verdien ganges med når den sendes gjennom koblingen. Ta for eksempel koblingen mellom en enkelt node i input-laget og en av nodene i det skjulte laget. La oss si at vekten i denne koblingen er 1,1. Hvis verdien i input-noden er 1, vil noden i det skjulte laget motta verdien 1,1. I det tilfelle sier vi at noden er aktivert, siden den sender en verdi. Hvis verdien i input-noden er 0, blir også verdien i den andre enden av koblingen 0. Da sier vi at noden ikke er aktivert.
I noden i det skjulte laget legges verdiene fra alle koblingene til input-laget lagt sammen. Så legges det til en verdi som kalles bias, som påvirker grenseverdien for når noden aktiveres. Hver enkelt node har sin egen bias, akkurat som hver enkelt kobling har sin egen vekt. Summen av alle input-verdiene og bias blir behandlet av en aktiveringsfunksjon. Aktiveringsfunksjonen er en matematisk formel som avgjør om noden skal aktiveres, altså sende en verdi videre, eller ikke. Hvis noden aktiveres, behandles summen med den matematiske formelen i aktiveringsfunksjonen, og resultatet sendes videre.
Det finnes mange ulike aktiveringsfunksjoner, men alle nodene i et lag bruker vanligvis den samme aktiveringsfunksjoner. Ulike aktiveringsfunksjoner kan gi hvert lag litt ulike egenskaper.
Hver eneste kobling mellom to noder har sin egen vekt og hver enkelt node har sin egen bias. Det er disse vi justerer når vi trener den kunstige intelligensen. Når alle vekter og biaser i det nevrale nettverket vårt er satt riktig, vil output-noden for verdien 6 være nærmest 1 når vi sender inn verdier fra et bilde av tallet 6 i modellen. Tilsvarende vil noden for verdien 2 bli aktivert hvis vi sender inn verdier for et bilde av et 2-tall. Summen av antall vekter og biaser i et nevralt nettverk kaller vi nettverkets parametre.
I vårt lille nettverk som kan kjenne igjen tall har vi 256 input-noder, noen hundre noder i det skjulte laget og ti noder i output-laget. Det gir oss noen tusen parametre som kan justeres når vi trener modellen.
Men hva med en modell som skal kjenne igjen ulike objekter i et stort fargebilde? Da kan vi ende opp med millioner av noder i inputlaget, og mange millioner i det skjulte laget. Det igjen kan gi oss milliarder av parametere. En slik modell vil kreve enorm datakraft, og vil derfor ikke skalere.
Hva om vi erstatter det enorme skjulte laget med flere, mindre skjulte lag? Da kan vi fordele ulike deler av oppgaven på de ulike lagene, og vi kan kombinere flere skjulte lag med litt ulike egenskaper.
Det er slik dagens kunstig intelligens-systemer fungerer. Ved å la flere skjulte lage jobbe med ulike deler av oppgaven, kan modellen utføre mye mer krevende oppgaver med relativt færre noder.
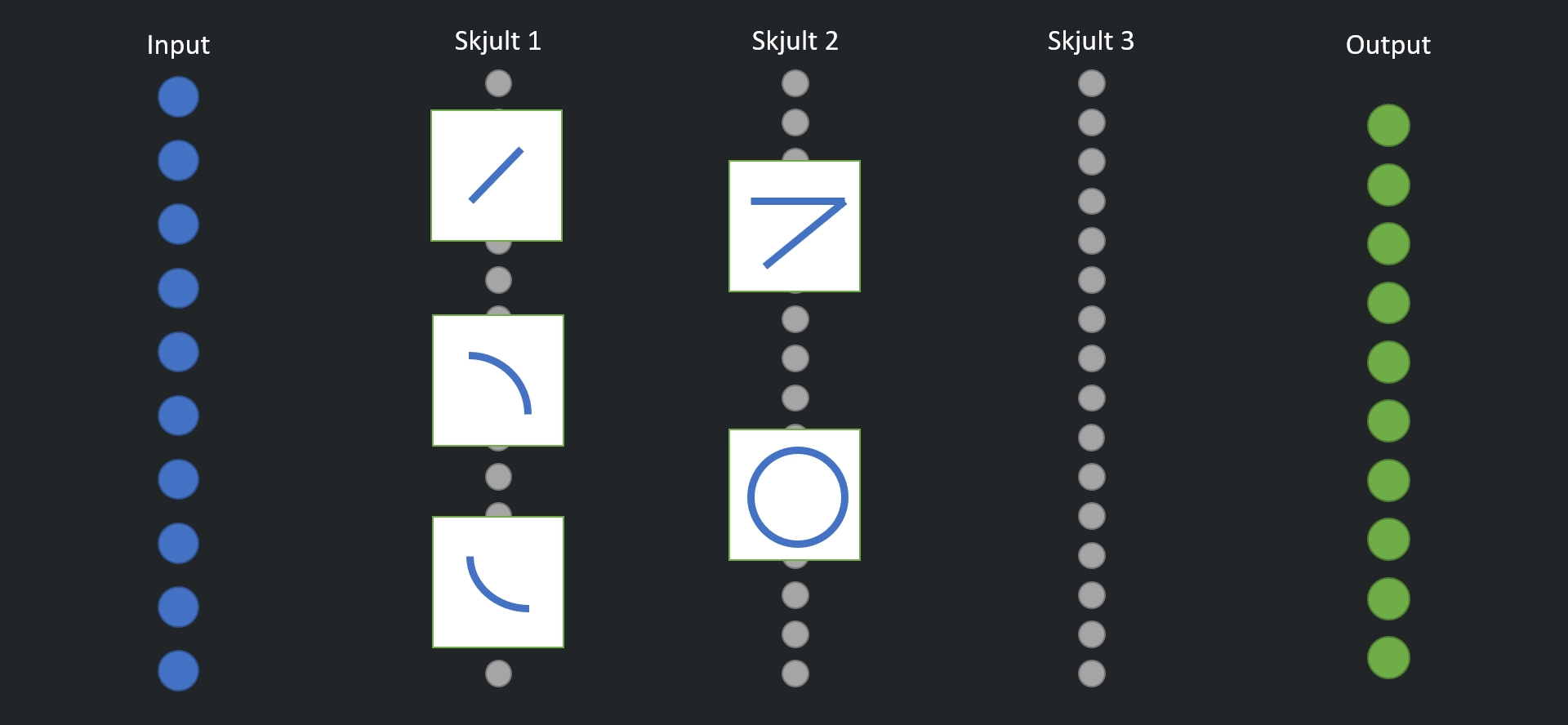
I vårt eksempel kan for eksempel det første skjulte laget kjenne igjen noe grunnleggende former, som linjer, buer og så videre. Det neste laget kan sette sammen de grunnleggende formene til mer avanserte figurer, og det tredje laget kan kombinere figurene til noe som minner om tallene vi ser etter.
Da kan nodene i flere av lagene gjenbrukes, ved at formene de kjenner igjen brukes i flere tall. Den samme buen går igjen i tallene 0, 3, 5, 6, 8 og 9. Noden som representerer denne buen vil aktiveres for alle disse tallene.
I tillegg til å bruke ulike aktiveringsfunksjoner i de forskjellige lagene, kan vi også variere måten lagene er koblet sammen på. I noen tilfeller kan nodene være koblet til andre noder i samme lag, mens i andre tilfeller kan noen noder hoppe over et lag, og kobles direkte til et tredje lag. Det gjøre at vi kan lage modeller med veldig avanserte funksjoner.
Denne typen variasjoner gjør at vi kan lage modeller som er spesielt egnet for å behandle bilder, tekst, lyd, dataanalyse og så videre.
Vi kan også koble sammen flere modeller som utfører ulike oppgaver. Et eksempel på dette finner vi i smarthøyttalere. De utnytter både språkmodeller og lydmodeller for å utføre oppgavene vi ber dem om:
Dette er en forenkling av hvordan kunstig intelligens fungerer, men gir et ganske riktig bilde av prinsippene det bygger på. Utviklingen av kunstig intelligens handler ikke bare om å lage større nevrale nettverk, men også om å finne smartere måter å koble sammen lagene på, og bedre aktiveringsfunksjoner.
Når ekspertene sier at vi ikke helt vet hvordan kunstig intelligens kommer frem til resultatene den gjør, så handler det først og fremst om at de matematiske regnestykkene er så store og kompliserte, at det er umulig for oss mennesker å håndtere.
Men uansett hvor avanserte kunstig intelligens-modellene blir, så gjelder det samme grunnprinsippet: Det er ikke magi, det er matematikk.
